近日,通信工程学院智能信息计算团队的研究成果《InstructDubber: Instruction-based Alignment for Zero-shot Movie Dubbing》被人工智能领域国际顶级会议The 40th AAAI Conference on Artificial Intelligence (AAAI 2026) 正式录用。第一作者为24级博士研究生张哲东,指导老师为颜成钢教授和刘春山教授,李亮研究员(中国科学院计算技术研究所)。
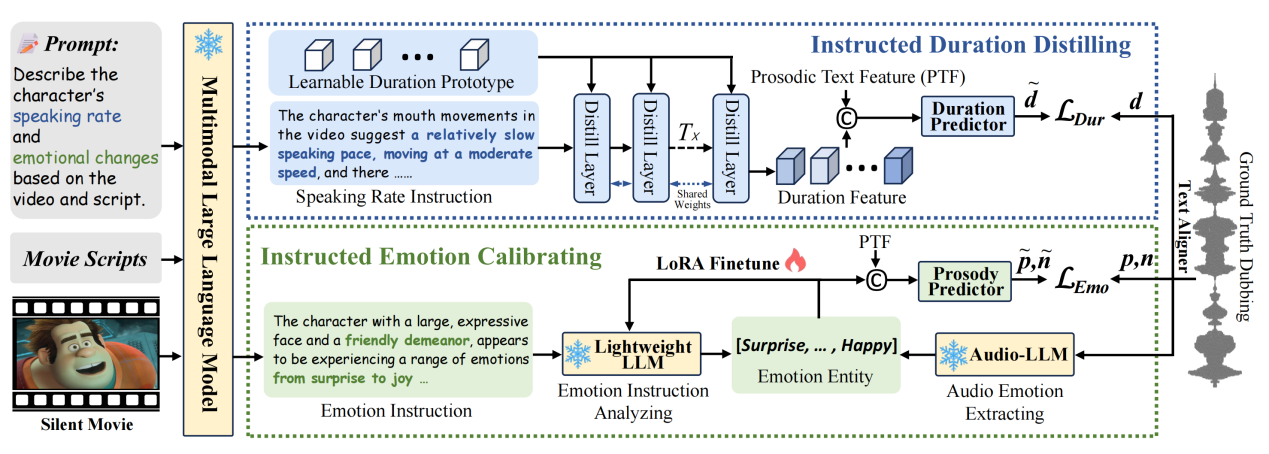
电影配音任务(Movie Dubbing,又称为视觉声音克隆,Visual Voice Cloning,V2C)旨在基于给定的台词脚本合成指定声音的语音,同时确保与角色视觉表演的口型同步及情感韵律一致。然而,现有基于视觉特征的对齐方法存在两大局限:(1)它们依赖复杂且手工设计的视觉预处理流程,包括人脸关键点检测与特征提取;(2)它们在未见过的视觉域中泛化能力较差,常导致配音的对齐与质量下降。为了解决这些问题,论文提出InstructDubber,一种基于指令的对齐配音方法,可同时实现鲁棒的域内配音与零样本配音。具体而言,论文首先将视频、脚本及相应提示输入多模态大语言模型,以生成关于视频中说话速度与情感状态的自然语言配音指令,从而在视觉域变化下保持稳健。其次,论文设计了一个指令引导的时长蒸馏模块,从说话速度指令中挖掘区分性时长线索,以预测与口型对齐的音素级发音时长。第三,为实现情感与韵律对齐,论文提出一个指令引导的情感校准模块,利用真实配音的情感标注对基于LLM的指令分析器进行微调,从而根据校准后的情感分析预测韵律。最后,将预测的时长与韵律信息及脚本一同输入音频解码器,生成与视频对齐的配音。大量实验结果表明,InstructDubber在三个主要基准上均显著优于现有最先进方法,无论是在域内还是零样本场景中都表现出色。
杭州电子科技大学“智能信息处理实验室”(HDU IIPLab)主任为颜成钢教授。实验室现有在职教师50余名,含5位国家级人才及多位省级人才。现有硕博生200余名,毕业生多就职于阿里巴巴、腾讯、字节跳动、海康威视、华为、网易等国内知名企业。实验室为学校交叉创新团队,拥有自由开放的学术氛围和国际前沿的研究方向。实验室采用与海内外知名高校、研究所(清华大学、北京大学、中国科学院、美国北卡罗来纳大学教堂山分校、澳大利亚悉尼科技大学等)联合培养制,长期致力于智能信息处理方面的研究,主要研究方向包括:机器学习、模式识别、计算机视觉、计算机图形学、医学影像处理、生物信息学等。
图文:张哲东
一审:刘春山
二审:邱一波
三审:孙闽红
